
浮動小数点数の複数ロード/ストア命令()
前回は浮動小数点数を1つずつ扱うスカラー型のロード/ストア命令でしたが、今回は複数の浮動小数点数を 1 命令でベクトルレジスタ (V0 - V31) にロード/ストアする命令です。 次の図の左側は LD1 命令で、 X1 レジスタが示しているメモリアドレス (X1 レジスタが格納している値の位置のメモリ) に入っている4つの単精度浮動小数点数を V0 レジスタに読み込む例です。右側はST1 命令で、 V0 レジスタに入っている4つの単精度浮動小数点数をX1 レジスタが示しているメモリに書き込みます。
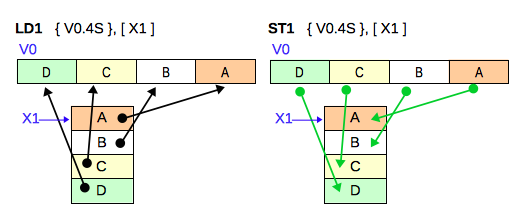
ベクトルなので 1次元、 2次元、3次元、4次元といった1組のデータに含まれる要素の数やメモリ内での数値の並び方の違いで複数の命令があります。 ベクトル型のロード命令には、LD1、LD2、LD3、LD4があり、対応するストア命令は ST1、ST2、ST3、ST4 がありますが、公式の ARM Architecture Reference Manual の解説はわかり易くありません。 ここでは、公式マニュアルより分かり易くなるように、データの動きを表した図とサンプルとして実際に命令を実行した結果も示すようにしました。
ベクトルレジスタの表記方法
ベクトルレジスタ (V0 - V31) には以下の表のように128ビットのレジスタを次の表のような複数のレーンに分けて使用します。レーンを示すインデックスは最も下位(右側) を 0 とします。インデックスで指定した1つのレーンにだけ読み書きする「シングル」系の命令と、レジスタ全体(128ビット)、または下半分(64ビット)に書き込む「マルチ」系の2種類があります。
| 型 | データサイズ | 個数 | インデックス |
|---|---|---|---|
| 8B | 8 ビット | 8 | 0..7 |
| 16B | 8 ビット | 16 | 0..15 |
| 4H | 16 ビット | 4 | 0..3 |
| 8H | 16 ビット | 8 | 0..7 |
| 2S | 32 ビット | 2 | 0..1 |
| 4S | 32 ビット | 4 | 0..3 |
| 1D | 64 ビット | 1 | 0 |
| 2D | 64 ビット | 2 | 0..1 |
ベクトルレジスタへは以下のように数値が格納されます。 図の中で 2D[0]、8H[5] という1つの数値を格納する場所がレーンです。インデックスを付ける場合は、V3.2S[1]、V3.4S[1] ではなく、V3.S[1] のように書くこともできます。
| Vn | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| byte 15 | byte 14 | byte 13 | byte 12 | byte 11 | byte 10 | byte 9 | byte 8 | byte 7 | byte 6 | byte 5 | byte 4 | byte 3 | byte 2 | byte 1 | byte 0 |
| 2D[1] | 2D[0] | ||||||||||||||
| 1D[0] | |||||||||||||||
| 4S[3] | 4S[2] | 4S[1] | 4S[0] | ||||||||||||
| 2S[1] | 2S[0] | ||||||||||||||
| 8H[7] | 8H[6] | 8H[5] | 8H[4] | 8H[3] | 8H[2] | 8H[1] | 8H[0] | ||||||||
| 4H[3] | 4H[2] | 4H[1] | 4H[0] | ||||||||||||
| 16B[15] | 16B[14] | 16B[13] | 16B[12] | 16B[11] | 16B[10] | 16B[9] | 16B[8] | 16B[7] | 16B[6] | 16B[5] | 16B[4] | 16B[3] | 16B[2] | 16B[1] | 16B[0] |
| 8B[7] | 8B[6] | 8B[5] | 8B[4] | 8B[3] | 8B[2] | 8B[1] | 8B[0] | ||||||||
実行例について
LDn / STn 命令は動作がわかりにくいので、実際に命令を実行した例を次のような形式で載せています。実行例では、すべて4バイトの単精度浮動小数点数(S)を使っています。 ベクトルレジスタには4つの数値を格納できます。 他のサイズの場合も同時に扱う数値の数は異なりますが、同じような動作となります。 最初の行に命令を示し、実行結果のレジスタの内容は、先頭が「 V1:」で始まる行に示しています。青字になっている部分は命令の実行で変化した部分です。
ld1 { v1.s } [0], [x1] // LD1 single
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 0.0000000 0.0000000 0.0000000 1.1345678E1
実行例ではメモリ中に浮動小数点数を格納しておいて、どのようにレジスタに 読み込まれるか調べます。 メモリには16個の単精度浮動小数点数を連続してメモリ上に用意します。 どの数値が使われたかわかりやすいように、指数がメモリ内の順番となるような数値としています。 例えば、指数が13の場合は X1 レジスタで指定したメモリ位置から13番目に格納されている数値を示します。
.single 1.1345678E01
.single -2.2345678E02
.single 3.3345678E03
.single -4.4345678E04
.single 5.5345678E05
.single -6.6345678E06
.single 7.7345678E07
.single -8.8345678E08
.single 9.9345678E09
.single -1.0000111E10
.single 1.1000111E11
.single -1.2000111E12
.single 1.3000111E13
.single -1.4000111E14
.single 1.5000111E15
.single -1.6000111E16
命令を実行する前に V1 から V4 のレジスタは、すべて 0.0 に設定しています。
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0] V1: 0.0000000 0.0000000 0.0000000 0.0000000 V2: 0.0000000 0.0000000 0.0000000 0.0000000 V3: 0.0000000 0.0000000 0.0000000 0.0000000 V4: 0.0000000 0.0000000 0.0000000 0.0000000
LD1 / ST1
LD1 / ST1命令は、単純な数値 (スカラー) の配列を 1 から 4 個のレジスタに一度に読み書きする命令です。 厳密には 1次元ベクトルは 1次元空間で正負の向きを持つ量のことですが、数値としてはスカラーと同じです。 LD1 / ST1命令が他のLDn / STn 系の命令と異なるところは、操作するレジスタを 1 つから 4 つまで 指定できることです。 他の命令では、LD2 / ST2 は 2 つのレジスタ、LD3 / ST3 は 3 つのレジスタ、 LD4 / ST4 は 4 つのレジスタと決まっています。 LD1 / ST1命令は 1 種類の数値のみ扱うため、一度に読み書きするデータを単精度浮動小数点数なら 16個 (64 バイト) までフルに扱うことができます。
LD1 / ST1(single)
LD1命令は、指定した1つのレジスタのインデックスで指定したレーンへ、ベースレジスタ(汎用レジスタ Xn または スタックポインタ SP) の示すメモリの番地に格納されている数値を1つ読み込みます。 ST1命令は、指定した1つのレジスタのインデックスで指定したレーンの数値を、ベースレジスタ(汎用レジスタ Xn または スタックポインタ SP) の示すメモリの番地に格納します。
指定したレーン以外は変化しないので、ベクトルレジスタの特定のレーンだけの読み書きが可能です。
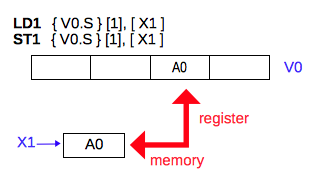
LD1 { Vt.T }[index], [Xn|SP]
LD1 { Vt.T }[index], [Xn|SP], #imm
LD1 { Vt.T }[index], [Xn|SP], Xm
ST1 { Vt.T }[index], [Xn|SP]
ST1 { Vt.T }[index], [Xn|SP], #imm
ST1 { Vt.T }[index], [Xn|SP], Xm
T = B, H, S, D
imm = 1, 2, 4, 8
インデックスの値を 0 から 3 まで変化させてロードした場合のベクタレジスタの値を示します。
ld1 { v1.s } [0], [x1] // LD1 single
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 0.0000000 0.0000000 0.0000000 1.1345678E1
ld1 { v1.s } [1], [x1] // LD1 single
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 0.0000000 0.0000000 1.1345678E1 0.0000000
ld1 { v1.s } [2], [x1] // LD1 single
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 0.0000000 1.1345678E1 0.0000000 0.0000000
ld1 { v1.s } [3], [x1] // LD1 single
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 1.1345678E1 0.0000000 0.0000000 0.0000000
LD1 / ST1(multi)
LD1 / ST1 命令の「マルチ」形式では、指定した4つまでのベクタレジスタのすべてのレーンのデータを読み書きします。 次の図はレジスタを 2 つ指定した場合を示します。 LD1ではメモリに格納された 8 個の数値をレジスタに順番に読み込みます。
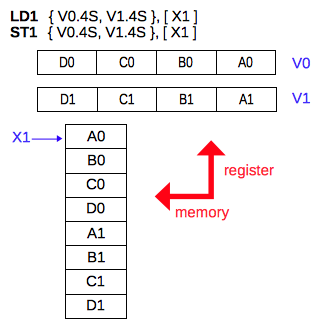
1 レジスタ分 (16バイト) を転送するバージョンです。 定数オフセット (#imm) を指定した場合は転送後に転送したデータサイズ分だけベースレジスタに加算されます。 レジスタ Xm を指定した場合は転送後に Xm の内容がベースレジスタに加算されます。
LD1 { Vt.T }, [Xn|SP]
LD1 { Vt.T }, [Xn|SP], #imm
LD1 { Vt.T }, [Xn|SP], Xm
ST1 { Vt.T }, [Xn|SP]
ST1 { Vt.T }, [Xn|SP], #imm
ST1 { Vt.T }, [Xn|SP], Xm
T = B, H, S, D
imm = 1, 2, 4, 8
2 レジスタ分 (32バイト) を転送するバージョン
LD1 { Vt.T, Vt2.T }, [Xn|SP]
LD1 { Vt.T, Vt2.T }, [Xn|SP], #imm
LD1 { Vt.T, Vt2.T }, [Xn|SP], Xm
ST1 { Vt.T, Vt2.T }, [Xn|SP]
ST1 { Vt.T, Vt2.T }, [Xn|SP], #imm
ST1 { Vt.T, Vt2.T }, [Xn|SP], Xm
T = B, H, S, D
imm = 2, 4, 8, 16
3 レジスタ分 (48バイト) を転送するバージョン
LD1 { Vt.T, Vt2.T, Vt3.T }, [Xn|SP]
LD1 { Vt.T, Vt2.T, Vt3.T }, [Xn|SP], #imm
LD1 { Vt.T, Vt2.T, Vt3.T }, [Xn|SP], Xm
ST1 { Vt.T, Vt2.T, Vt3.T }, [Xn|SP]
ST1 { Vt.T, Vt2.T, Vt3.T }, [Xn|SP], #imm
ST1 { Vt.T, Vt2.T, Vt3.T }, [Xn|SP], Xm
T = B, H, S, D
imm = 3, 6, 12, 24
4 レジスタ分 (64バイト) を転送するバージョン
LD1 { Vt.T, Vt2.T, Vt3.T, Vt4.T }, [Xn|SP]
LD1 { Vt.T, Vt2.T, Vt3.T, Vt4.T }, [Xn|SP], #imm
LD1 { Vt.T, Vt2.T, Vt3.T, Vt4.T }, [Xn|SP], Xm
ST1 { Vt.T, Vt2.T, Vt3.T, Vt4.T }, [Xn|SP]
ST1 { Vt.T, Vt2.T, Vt3.T, Vt4.T }, [Xn|SP], #imm
ST1 { Vt.T, Vt2.T, Vt3.T, Vt4.T }, [Xn|SP], Xm
T = B, H, S, D
imm = 4, 8, 16, 32
メモリからレジスタへのロードを、1つのレジスタの下位64ビットに行った場合の実行例です。 単精度浮動小数点数2つがロードされることを確認できます。
ld1 { v1.2s }, [x1] // LD1 multi 1reg
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 0.0000000 0.0000000 -2.2345678E2 1.1345678E1
メモリからレジスタへのロードを、レジスタ数の指定を 1 つから 4 つまで順次増やして行った場合の実行例です。
ld1 { v1.4s }, [x1] // LD1 multi 1reg
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: -4.4345679E4 3.3345678E3 -2.2345678E2 1.1345678E1
ld1 { v1.4s, v2.4s }, [x1] // LD1 multi 2reg
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: -4.4345679E4 3.3345678E3 -2.2345678E2 1.1345678E1
V2: -8.8345676E8 7.7345680E7 -6.6345680E6 5.5345674E5
ld1 { v1.4s, v2.4s, v3.4s }, [x1] // LD1 multi 3reg
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: -4.4345679E4 3.3345678E3 -2.2345678E2 1.1345678E1
V2: -8.8345676E8 7.7345680E7 -6.6345680E6 5.5345674E5
V3: -1.2000110E12 1.1000111E11 -1.0000110E10 9.9345674E9
ld1 { v1.4s, v2.4s, v3.4s, v4.4s }, [x1] // LD1 multi 4reg
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: -4.4345679E4 3.3345678E3 -2.2345678E2 1.1345678E1
V2: -8.8345676E8 7.7345680E7 -6.6345680E6 5.5345674E5
V3: -1.2000110E12 1.1000111E11 -1.0000110E10 9.9345674E9
V4: -1.6000111E16 1.5000111E15 -1.4000111E14 1.3000111E13
LD1R
ロード命令にはメモリ上の 1 つの数値を 1 つのレジスタの全レーンへコピーする LD1R があります。ストア命令には対応する形式はありません。
LD1R { Vt.T }, [Xn|SP]
LD1R { Vt.T }, [Xn|SP], #imm
LD1R { Vt.T }, [Xn|SP], Xm
T = B, H, S, D
imm = 1, 2, 4, 8
ベクタレジスタの 4 つのレーンに同じ値が設定されていることが確認できます。
ld1r { v1.4s }, [x1] // LD1R
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 1.1345678E1 1.1345678E1 1.1345678E1 1.1345678E1
命令のエンコード
LD1 命令のエンコード
| LD1 | 31 | 30 | 29 | 28 | 27 | 26 | 25 | 24 | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | 11 | 10 | 09 | 08 | 07 | 06 | 05 | 04 | 03 | 02 | 01 | 00 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (single) No offset | 0 | Q | 0 0 1 1 0 1 0 | 1 | 0 | 0 0 0 0 0 | x x 0 | S | size | Rn | Rt | |||||||||||||||||||||
| (single) post index | 0 | Q | 0 0 1 1 0 1 1 | 1 | 0 | Rm | x x 0 | S | size | Rn | Rt | |||||||||||||||||||||
| (multi) No offset | 0 | Q | 0 0 1 1 0 0 0 | 1 | 0 0 0 0 0 0 | x x 1 x | size | Rn | Rt | |||||||||||||||||||||||
| (multi) post index | 0 | Q | 0 0 1 1 0 0 1 | 1 | 0 | Rm | x x 1 x | size | Rn | Rt | ||||||||||||||||||||||
| LD1R No offset | 0 | Q | 0 0 1 1 0 1 0 | 1 | 0 | 0 0 0 0 0 | 1 1 0 | 0 | size | Rn | Rt | |||||||||||||||||||||
| LD1R post index | 0 | Q | 0 0 1 1 0 1 1 | 1 | 0 | Rm | 1 1 0 | 0 | size | Rn | Rt | |||||||||||||||||||||
ST1 命令のエンコード
| ST1 | 31 | 30 | 29 | 28 | 27 | 26 | 25 | 24 | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | 11 | 10 | 09 | 08 | 07 | 06 | 05 | 04 | 03 | 02 | 01 | 00 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (single) No offset | 0 | Q | 0 0 1 1 0 1 0 | 0 | 0 | 0 0 0 0 0 | x x 0 | S | size | Rn | Rt | |||||||||||||||||||||
| (single) post index | 0 | Q | 0 0 1 1 0 1 1 | 0 | 0 | Rm | x x 0 | S | size | Rn | Rt | |||||||||||||||||||||
| (multi) No offset | 0 | Q | 0 0 1 1 0 0 0 | 0 | 0 0 0 0 0 0 | x x 1 x | size | Rn | Rt | |||||||||||||||||||||||
| (multi) post index | 0 | Q | 0 0 1 1 0 0 1 | 0 | 0 | Rm | x x 1 x | size | Rn | Rt | ||||||||||||||||||||||
エンコードの共通部分
LDn / STn 命令のエンコードで共通に現れるビットパターンです。ST1 の場合のアセンブリ命令を例としています。
single オフセットなしアドレッシング
数値のメモリ中の先頭位置を示すベースレジスタ (Xn|SP) を命令の実行後に書き換えないアドレッシングです。
opcode は bit 15 - 13 のビットパターンです。 S はbit 12 です。
| bit | opcode | size | S | ST1の場合 |
|---|---|---|---|---|
| 8 | 000 | - | - | ST1 { Vt.B }[index], [Xn|SP] |
| 16 | 010 | x0 | - | ST1 { Vt.H }[index], [Xn|SP] |
| 32 | 100 | 00 | - | ST1 { Vt.S }[index], [Xn|SP] |
| 64 | 100 | 01 | 1 | ST1 { Vt.D }[index], [Xn|SP] |
multi オフセットなしアドレッシング
数値のメモリ中の先頭位置を示すベースレジスタ (Xn|SP) を命令の実行後に書き換えないアドレッシングです。
opcode は bit 15 - 12 のビットパターンです。
| # reg | opcode | ST1の場合 |
|---|---|---|
| 1 | 0111 | ST1 { Vt.T }, [Xn|SP] |
| 2 | 1010 | ST1 { Vt.T, Vt2.T }, [Xn|SP] |
| 3 | 0110 | ST1 { Vt.T, Vt2.T, Vt3.T }, [Xn|SP] |
| 4 | 0010 | ST1 { Vt.T, Vt2.T, Vt3.T, Vt4.T }, [Xn|SP] |
single ポストインデックスアドレッシング
数値のメモリ中の先頭位置を示すベースレジスタ (Xn|SP) を命令の実行後に、次の位置を示すように書き換えるアドレッシングモードです。 定数 (即値) オフセットの値を設定するビットが用意されていないところがミソ (工夫されているところ) です。 定数 (即値) オフセットの場合は、アセンブラが転送するバイト数と指定された定数をチェックして異なる場合は、 「Error: invalid post-increment amount at operand 2」というエラーとなります。 つまり、定数オフセットの場合は転送するバイト数しか指定できないわけです。
| bit | offset | Rm | opcode | size | S | ST1の場合 |
|---|---|---|---|---|---|---|
| 8 | imm | 11111 | 000 | - | - | ST1 { Vt.B }[index], [Xn|SP], #1 |
| 8 | reg | - | 000 | - | - | ST1 { Vt.B }[index], [Xn|SP], Xm |
| 16 | imm | 11111 | 010 | x0 | - | ST1 { Vt.H }[index], [Xn|SP], #2 |
| 16 | reg | - | 010 | x0 | - | ST1 { Vt.H }[index], [Xn|SP], Xm |
| 32 | imm | 11111 | 100 | 00 | - | ST1 { Vt.S }[index], [Xn|SP], #4 |
| 32 | reg | - | 100 | 00 | - | ST1 { Vt.S }[index], [Xn|SP], Xm |
| 64 | imm | 11111 | 100 | 01 | 0 | ST1 { Vt.D }[index], [Xn|SP], #8 |
| 64 | reg | - | 100 | 01 | 0 | ST1 { Vt.D }[index], [Xn|SP], Xm |
multi ポストインデックスアドレッシング
数値のメモリ中の先頭位置を示すベースレジスタ (Xn|SP) を命令の実行後に、次の位置を示すように書き換えるアドレッシングモードです。 定数オフセットの場合は、転送するバイト数を指定する必要があります。
| # reg | offset | Rm | opcode | ST1の場合 |
|---|---|---|---|---|
| 1 | imm | 11111 | 0111 | ST1 { Vt.T }, [Xn|SP], #imm |
| 1 | reg | - | 0111 | ST1 { Vt.T }, [Xn|SP], Xm |
| 2 | imm | 11111 | 1010 | ST1 { Vt.T, Vt2.T }, [Xn|SP], #imm |
| 2 | reg | - | 1010 | ST1 { Vt.T, Vt2.T }, [Xn|SP], Xm |
| 3 | imm | 11111 | 0110 | ST1 { Vt.T, Vt2.T, Vt3.T }, [Xn|SP], #imm |
| 3 | reg | - | 0110 | ST1 { Vt.T, Vt2.T, Vt3.T }, [Xn|SP], Xm |
| 4 | imm | 11111 | 0010 | ST1 { Vt.T, Vt2.T, Vt3.T, Vt4.T }, [Xn|SP], #imm |
| 4 | reg | - | 0010 | ST1 { Vt.T, Vt2.T, Vt3.T, Vt4.T }, [Xn|SP], Xm |
レジスター指定
第30ビットの Q はレジスタ幅に128ビットを指定する場合は1、64ビットでは 0 となります。 第10、11ビットの size は以下のようにデータサイズの指定となっています。
| T | size | Q |
|---|---|---|
| 8B | 00 | 0 |
| 16B | 00 | 1 |
| 4H | 01 | 0 |
| 8H | 01 | 1 |
| 2S | 10 | 0 |
| 4S | 10 | 1 |
| 1D | 11 | 0 |
| 2D | 11 | 1 |
LD2 / ST2
2 種類の数値を含む構造体 (2次元ベクトル) 場合、2次元ベクトルの配列を要素の種類別に 2 個のレジスタに一度に読み書きする命令です。たとえば、2次元の座標値 (x, y) の配列を x 座標を V1 レジスタ、y 座標を V2 レジスタに読み込むような場合です。
LD2 / ST2(single)
メモリに格納されている 2 種類の数値からなるデータの 1 組を、2 つのレジスタの指定した 1 つのレーンへ読み書きします。
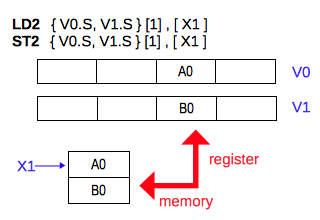
LD2 { Vt.T, Vt2.T }[index], [Xn|SP]
LD2 { Vt.T, Vt2.T }[index], [Xn|SP], #imm
LD2 { Vt.T, Vt2.T }[index], [Xn|SP], Xm
ST2 { Vt.T, Vt2.T }[index], [Xn|SP]
ST2 { Vt.T, Vt2.T }[index], [Xn|SP], #imm
ST2 { Vt.T, Vt2.T }[index], [Xn|SP], Xm
T = B, H, S, D
imm = 2, 4, 8, 16
次の例では、メモリに格納されている 2 つの数値が、2 つのレジスタの右から2番めのレーンへ読み込まれています。
ld2 { v1.s, v2.s }[1], [x1] // LD2 single
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 0.0000000 0.0000000 1.1345678E1 0.0000000
V2: 0.0000000 0.0000000 -2.2345678E2 0.0000000
LD2 / ST2(multi)
メモリに格納されている 2 種類の数値から構成されるデータの複数の組を、指定した 2 つのレジスタに対して読み書きします。データのサイズによって、16個のバイトデータ(16B)、8個の半精度浮動小数点数(8H)、4個の単精度浮動小数点数(4S)、2個の倍精度浮動小数点数(2D) を一度に 2 つのベクトルレジスタに対して読み書きします。 各々のデータのサイズにおいて、8B、4H、2S、1D のように半分の個数を指定することもできます。
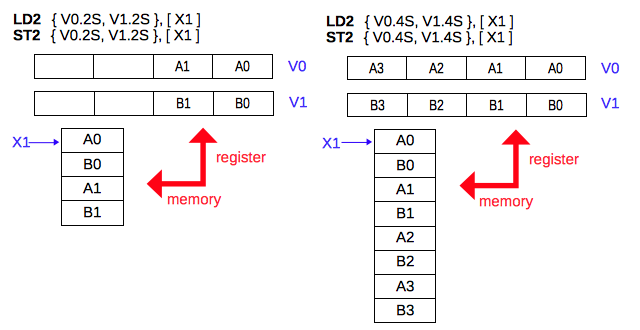
LD2 { Vt.T, Vt2.T }, [Xn|SP]
LD2 { Vt.T, Vt2.T }, [Xn|SP], #imm
LD2 { Vt.T, Vt2.T }, [Xn|SP], Xm
ST2 { Vt.T, Vt2.T }, [Xn|SP]
ST2 { Vt.T, Vt2.T }, [Xn|SP], #imm
ST2 { Vt.T, Vt2.T }, [Xn|SP], Xm
T = B, H, S, D
imm = 2, 4, 8, 16
次の例では、転送先として64ビット(2S) を指定すると、メモリ上の4つの数値が 2つのレジスタの2つのレーンにコピーされるのが確認できます。
ld2 { v1.2s, v2.2s }, [x1] // LD2 multi
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 0.0000000 0.0000000 3.3345678E3 1.1345678E1
V2: 0.0000000 0.0000000 -4.4345679E4 -2.2345678E2
同じように、転送先として128ビット(4S) を指定すると、メモリ上の 8 つの数値が 2つのレジスタの4つのレーンにコピーされるのが確認できます。
ld2 { v1.4s, v2.4s }, [x1] // LD2 multi
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 7.7345680E7 5.5345674E5 3.3345678E3 1.1345678E1
V2: -8.8345676E8 -6.6345680E6 -4.4345679E4 -2.2345678E2
LD2R
ロード命令にはメモリ上の 2 つの数値を 各レジスタの全レーンへコピーする LD2R があります。 ストア命令には対応する形式はありません。
LD2R { Vt.T, Vt2.T }, [Xn|SP]
LD2R { Vt.T, Vt2.T }, [Xn|SP], #imm
LD2R { Vt.T, Vt2.T }, [Xn|SP], Xm
T = B, H, S, D
imm = 2, 4, 8, 16
次の例では、メモリ上の先頭の数値が1つ目のレジスタの全レーンにコピーされ、 2番めの数値が次のレジスタの全レーンにコピーされるのが確認できます。
ld2r { v1.4s, v2.4s }, [x1] // LD2 multi
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 1.1345678E1 1.1345678E1 1.1345678E1 1.1345678E1
V2: -2.2345678E2 -2.2345678E2 -2.2345678E2 -2.2345678E2
命令のエンコード
LD2命令のエンコード
| LD2 | 31 | 30 | 29 | 28 | 27 | 26 | 25 | 24 | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | 11 | 10 | 09 | 08 | 07 | 06 | 05 | 04 | 03 | 02 | 01 | 00 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (single) No offset | 0 | Q | 0 0 1 1 0 1 0 | 1 | 1 | 0 0 0 0 0 | x x 0 | S | size | Rn | Rt | |||||||||||||||||||||
| (single) post index | 0 | Q | 0 0 1 1 0 1 1 | 1 | 1 | Rm | x x 0 | S | size | Rn | Rt | |||||||||||||||||||||
| (multi) No offset | 0 | Q | 0 0 1 1 0 0 0 | 1 | 0 0 0 0 0 0 | 1 0 0 0 | size | Rn | Rt | |||||||||||||||||||||||
| (multi) post index | 0 | Q | 0 0 1 1 0 0 1 | 1 | 0 | Rm | 1 0 0 0 | size | Rn | Rt | ||||||||||||||||||||||
| LD2R No offset | 0 | Q | 0 0 1 1 0 1 0 | 1 | 1 | 0 0 0 0 0 | 1 1 0 | 0 | size | Rn | Rt | |||||||||||||||||||||
| LD2R post index | 0 | Q | 0 0 1 1 0 1 1 | 1 | 1 | Rm | 1 1 0 | 0 | size | Rn | Rt | |||||||||||||||||||||
ST2命令のエンコード
| ST2 | 31 | 30 | 29 | 28 | 27 | 26 | 25 | 24 | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | 11 | 10 | 09 | 08 | 07 | 06 | 05 | 04 | 03 | 02 | 01 | 00 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (single) No offset | 0 | Q | 0 0 1 1 0 1 0 | 0 | 1 | 0 0 0 0 0 | x x 0 | S | size | Rn | Rt | |||||||||||||||||||||
| (single) post index | 0 | Q | 0 0 1 1 0 1 1 | 0 | 1 | Rm | x x 0 | S | size | Rn | Rt | |||||||||||||||||||||
| (multi) No offset | 0 | Q | 0 0 1 1 0 0 0 | 0 | 0 0 0 0 0 0 | 1 0 0 0 | size | Rn | Rt | |||||||||||||||||||||||
| (multi) post index | 0 | Q | 0 0 1 1 0 0 1 | 0 | 0 | Rm | 1 0 0 0 | size | Rn | Rt | ||||||||||||||||||||||
LD3 / ST3
構造体が 3 種類の数値を含む場合、構造体の配列を要素の種類別に 3 個のレジスタに一度に読み書きする命令です。たとえば、3次元の座標値 (x, y, z) の配列を x 座標を V1 レジスタ、y 座標を V2 レジスタ、z 座標を V3 レジスタに読み込むような場合です。
LD3 / ST3(single)
メモリに格納されている 3 種類の数値からなるデータの 1 組を、3 つのレジスタの指定した 1 つのレーンへ読み書きします。
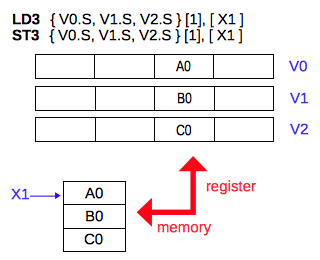
LD3 { Vt.T, Vt2.T, Vt3.T }[index], [Xn|SP]
LD3 { Vt.T, Vt2.T, Vt3.T }[index], [Xn|SP], #imm
LD3 { Vt.T, Vt2.T, Vt3.T }[index], [Xn|SP], Xm
ST3 { Vt.T, Vt2.T, Vt3.T }[index], [Xn|SP]
ST3 { Vt.T, Vt2.T, Vt3.T }[index], [Xn|SP], #imm
ST3 { Vt.T, Vt2.T, Vt3.T }[index], [Xn|SP], Xm
T = B, H, S, D
imm = 3, 6, 12, 24
次の例では、メモリに格納されている 3 つの数値が、3 つのレジスタの右から 3番めのレーンへ読み込まれています。
ld3 { v1.s, v2.s, v3.s }[2], [x1] // LD3 single
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 0.0000000 1.1345678E1 0.0000000 0.0000000
V2: 0.0000000 -2.2345678E2 0.0000000 0.0000000
V3: 0.0000000 3.3345678E3 0.0000000 0.0000000
LD3 / ST3(multi)
メモリに格納されている 3 種類の数値から構成されるデータの複数の組を、指定した 3 つのレジスタに対して読み書きします。データのサイズによって、16個のバイトデータ(16B)、8個の半精度浮動小数点数(8H)、4個の単精度浮動小数点数(4S)、2個の倍精度浮動小数点数(2D) を一度に 3 つのベクトルレジスタに対して読み書きします。 各々のデータのサイズにおいて、8B、4H、2S、1D のように半分の個数を指定することもできます。
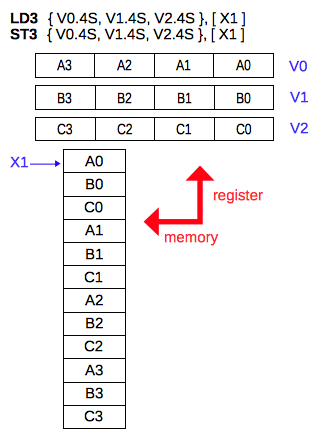
LD3 { Vt.T, Vt2.T, Vt3.T }, [Xn|SP]
LD3 { Vt.T, Vt2.T, Vt3.T }, [Xn|SP], #imm
LD3 { Vt.T, Vt2.T, Vt3.T }, [Xn|SP], Xm
ST3 { Vt.T, Vt2.T, Vt3.T }, [Xn|SP]
ST3 { Vt.T, Vt2.T, Vt3.T }, [Xn|SP], #imm
ST3 { Vt.T, Vt2.T, Vt3.T }, [Xn|SP], Xm
T = B, H, S, D
imm = 3, 6, 12, 24
次の例では、転送先として64ビット(2S) を指定すると、メモリ上の 6 つの数値が 3 つのレジスタの2つのレーンにコピーされるのが確認できます。
ld3 { v1.2s, v2.2s, v3.2s }, [x1] // LD3 multi
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 0.0000000 0.0000000 -4.4345679E4 1.1345678E1
V2: 0.0000000 0.0000000 5.5345674E5 -2.2345678E2
V3: 0.0000000 0.0000000 -6.6345680E6 3.3345678E3
同じように、128ビット(4S) を指定すると、メモリ上の 12個の数値が 3つのレジスタの4つのレーンにコピーされるのが確認できます。
ld3 { v1.4s, v2.4s, v3.4s }, [x1] // LD3 multi
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: -1.0000110E10 7.7345680E7 -4.4345679E4 1.1345678E1
V2: 1.1000111E11 -8.8345676E8 5.5345674E5 -2.2345678E2
V3: -1.2000110E12 9.9345674E9 -6.6345680E6 3.3345678E3
LD3R
ロード命令にはメモリ上の 3 つの数値を 各レジスタの全レーンへコピーする LD3R があります。 ストア命令には対応する形式はありません。
LD3R { Vt.T, Vt2.T, Vt3.T }, [Xn|SP]
LD3R { Vt.T, Vt2.T, Vt3.T }, [Xn|SP], #imm
LD3R { Vt.T, Vt2.T, Vt3.T }, [Xn|SP], Xm
ld3r { v1.4s, v2.4s, v3.4s }, [x1] // LD3 multi
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 1.1345678E1 1.1345678E1 1.1345678E1 1.1345678E1
V2: -2.2345678E2 -2.2345678E2 -2.2345678E2 -2.2345678E2
V3: 3.3345678E3 3.3345678E3 3.3345678E3 3.3345678E3
命令のエンコード
LD3 命令のエンコード
| LD3 | 31 | 30 | 29 | 28 | 27 | 26 | 25 | 24 | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | 11 | 10 | 09 | 08 | 07 | 06 | 05 | 04 | 03 | 02 | 01 | 00 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (single) No offset | 0 | Q | 0 0 1 1 0 1 0 | 1 | 0 | 0 0 0 0 0 | x x 1 | S | size | Rn | Rt | |||||||||||||||||||||
| (single) post index | 0 | Q | 0 0 1 1 0 1 1 | 1 | 0 | Rm | x x 1 | S | size | Rn | Rt | |||||||||||||||||||||
| (multi) No offset | 0 | Q | 0 0 1 1 0 0 0 | 1 | 0 0 0 0 0 0 | 0 1 0 0 | size | Rn | Rt | |||||||||||||||||||||||
| (multi) post index | 0 | Q | 0 0 1 1 0 0 1 | 1 | 0 | Rm | 0 1 0 0 | size | Rn | Rt | ||||||||||||||||||||||
| LD3R No offset | 0 | Q | 0 0 1 1 0 1 0 | 1 | 0 | 0 0 0 0 0 | 1 1 1 | 0 | size | Rn | Rt | |||||||||||||||||||||
| LD3R post index | 0 | Q | 0 0 1 1 0 1 1 | 1 | 0 | Rm | 1 1 1 | 0 | size | Rn | Rt | |||||||||||||||||||||
ST3 命令のエンコード
| ST3 | 31 | 30 | 29 | 28 | 27 | 26 | 25 | 24 | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | 11 | 10 | 09 | 08 | 07 | 06 | 05 | 04 | 03 | 02 | 01 | 00 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (single) No offset | 0 | Q | 0 0 1 1 0 1 0 | 1 | 0 | 0 0 0 0 0 | x x 1 | S | size | Rn | Rt | |||||||||||||||||||||
| (single) post index | 0 | Q | 0 0 1 1 0 1 1 | 1 | 0 | Rm | x x 1 | S | size | Rn | Rt | |||||||||||||||||||||
| (multi) No offset | 0 | Q | 0 0 1 1 0 0 0 | 0 | 0 0 0 0 0 0 | 0 1 0 0 | size | Rn | Rt | |||||||||||||||||||||||
| (multi) post index | 0 | Q | 0 0 1 1 0 0 1 | 0 | 0 | Rm | 0 1 0 0 | size | Rn | Rt | ||||||||||||||||||||||
LD4 / ST4
構造体が 4 種類の数値を含む場合、構造体の配列を要素の種類別に 4 個のレジスタに一度に読み書きする命令です。たとえば、4次元の座標値 (x, y, z, w) の配列を x 座標を V1 レジスタ、y 座標を V2 レジスタ、z 座標を V3 レジスタ、w 座標を V4 レジスタに読み込むような場合です。
LD4/ST4(single)
メモリに格納されている 4 種類の数値からなるデータの 1 組を、4 つのレジスタの指定した 1 つのレーンへ読み書きします。
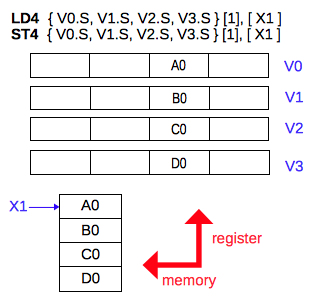
LD4 { Vt.T, Vt2.T, Vt3.T, Vt4.T }[index], [Xn|SP]
LD4 { Vt.T, Vt2.T, Vt3.T, Vt4.T }[index], [Xn|SP], #imm
LD4 { Vt.T, Vt2.T, Vt3.T, Vt4.T }[index], [Xn|SP], Xm
ST4 { Vt.T, Vt2.T, Vt3.T, Vt4.T }[index], [Xn|SP]
ST4 { Vt.T, Vt2.T, Vt3.T, Vt4.T }[index], [Xn|SP], #imm
ST4 { Vt.T, Vt2.T, Vt3.T, Vt4.T }[index], [Xn|SP], Xm
T = B, H, S, D
imm = 4, 8, 16, 32
次の例では、メモリに格納されている 4 つの数値が、4 つのレジスタの右から 4番め (左端) のレーンへ読み込まれています。
ld4 { v1.s, v2.s, v3.s, v4.s } [3], [x1] // LD4 single
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 1.1345678E1 0.0000000 0.0000000 0.0000000
V2: -2.2345678E2 0.0000000 0.0000000 0.0000000
V3: 3.3345678E3 0.0000000 0.0000000 0.0000000
V4: -4.4345679E4 0.0000000 0.0000000 0.0000000
LD4 / ST4(multi)
メモリに格納されている 4 種類の数値から構成されるデータの複数の組を、指定した 4 つのレジスタに対して読み書きします。データのサイズによって、16個のバイトデータ(16B)、8個の半精度浮動小数点数(8H)、4個の単精度浮動小数点数(4S)、2個の倍精度浮動小数点数(2D) を一度に 4 つのベクトルレジスタに対して読み書きします。 各々のデータのサイズにおいて、8B、4H、2S、1D のように半分の個数を指定することもできます。
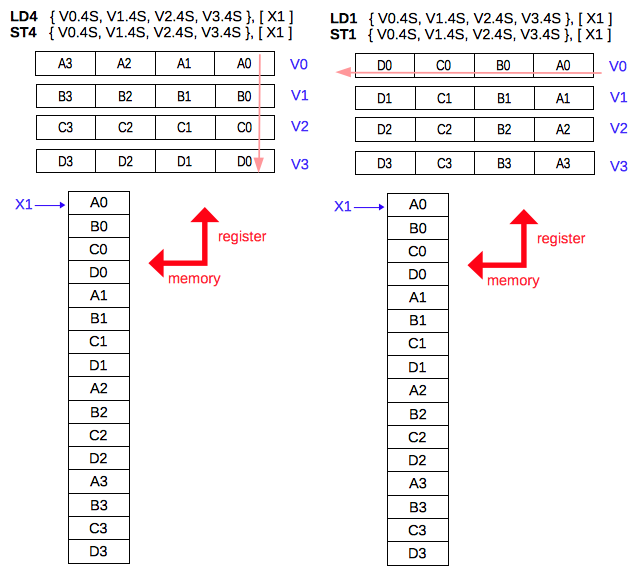
上の図の右側の4レジスタを指定したLD1/ST1命令と左側のLD4/ST4命令の違いに注意してください。
LD4 { Vt.T, Vt2.T, Vt3.T, Vt4.T }, [Xn|SP]
LD4 { Vt.T, Vt2.T, Vt3.T, Vt4.T }, [Xn|SP], #imm
LD4 { Vt.T, Vt2.T, Vt3.T, Vt4.T }, [Xn|SP], Xm
ST4 { Vt.T, Vt2.T, Vt3.T, Vt4.T }, [Xn|SP]
ST4 { Vt.T, Vt2.T, Vt3.T, Vt4.T }, [Xn|SP], #imm
ST4 { Vt.T, Vt2.T, Vt3.T, Vt4.T }, [Xn|SP], Xm
T = B, H, S, D
imm = 4, 8, 16, 32
16個の数値を1命令でロードしていることが確認できます。 メモリに格納されている順に指数が設定されているので、メモリ内でのデータの配置とレジスタにロードされた後の配置を比べることができます。LD1 の 4 レジスタを転送する場合との違いも確認してください。
ld4 { v1.4s, v2.4s, v3.4s, v4.4s }, [x1] // LD4 multi
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 1.3000111E13 9.9345674E9 5.5345674E5 1.1345678E1
V2: -1.4000111E14 -1.0000110E10 -6.6345680E6 -2.2345678E2
V3: 1.5000111E15 1.1000111E11 7.7345680E7 3.3345678E3
V4: -1.6000111E16 -1.2000110E12 -8.8345676E8 -4.4345679E4
LD4R
ロード命令にはメモリ上の 4 つの数値を 4つのレジスタの全レーンへコピーする LD4R があります。 ストア命令には対応する形式はありません。
LD4R { Vt.T, Vt2.T, Vt3.T, Vt4.T }, [Xn|SP]
LD4R { Vt.T, Vt2.T, Vt3.T, Vt4.T }, [Xn|SP], imm
LD4R { Vt.T, Vt2.T, Vt3.T, Vt4.T }, [Xn|SP], Xm
ld4r { v1.4s, v2.4s, v3.4s, v4.4s }, [x1] // LD4 multi
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 1.1345678E1 1.1345678E1 1.1345678E1 1.1345678E1
V2: -2.2345678E2 -2.2345678E2 -2.2345678E2 -2.2345678E2
V3: 3.3345678E3 3.3345678E3 3.3345678E3 3.3345678E3
V4: -4.4345679E4 -4.4345679E4 -4.4345679E4 -4.4345679E4
命令のエンコード
LD4命令のエンコード
| LD4 | 31 | 30 | 29 | 28 | 27 | 26 | 25 | 24 | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | 11 | 10 | 09 | 08 | 07 | 06 | 05 | 04 | 03 | 02 | 01 | 00 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (single) No offset | 0 | Q | 0 0 1 1 0 1 0 | 1 | 1 | 0 0 0 0 0 | x x 1 | S | size | Rn | Rt | |||||||||||||||||||||
| (single) post index | 0 | Q | 0 0 1 1 0 1 1 | 1 | 1 | Rm | x x 1 | S | size | Rn | Rt | |||||||||||||||||||||
| (multi) No offset | 0 | Q | 0 0 1 1 0 0 0 | 1 | 0 0 0 0 0 0 | 0 0 0 0 | size | Rn | Rt | |||||||||||||||||||||||
| (multi) post index | 0 | Q | 0 0 1 1 0 0 1 | 1 | 0 | Rm | 0 0 0 0 | size | Rn | Rt | ||||||||||||||||||||||
| LD4R No offset | 0 | Q | 0 0 1 1 0 1 0 | 1 | 1 | 0 0 0 0 0 | 1 1 1 | 0 | size | Rn | Rt | |||||||||||||||||||||
| LD4R post index | 0 | Q | 0 0 1 1 0 1 1 | 1 | 1 | Rm | 1 1 1 | 0 | size | Rn | Rt | |||||||||||||||||||||
ST4命令のエンコード
| ST4 | 31 | 30 | 29 | 28 | 27 | 26 | 25 | 24 | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | 11 | 10 | 09 | 08 | 07 | 06 | 05 | 04 | 03 | 02 | 01 | 00 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (single) No offset | 0 | Q | 0 0 1 1 0 1 0 | 0 | 1 | 0 0 0 0 0 | x x 1 | S | size | Rn | Rt | |||||||||||||||||||||
| (single) post index | 0 | Q | 0 0 1 1 0 1 1 | 0 | 1 | Rm | x x 1 | S | size | Rn | Rt | |||||||||||||||||||||
| (multi) No offset | 0 | Q | 0 0 1 1 0 0 0 | 0 | 0 0 0 0 0 0 | 0 0 0 0 | size | Rn | Rt | |||||||||||||||||||||||
| (multi) post index | 0 | Q | 0 0 1 1 0 0 1 | 0 | 0 | Rm | 0 0 0 0 | size | Rn | Rt | ||||||||||||||||||||||
LDn / STn 命令の実行と結果の確認
LDn / STn 命令を実際に実行して、結果を確認するためのコードです。 実行する命令を表示してから、実行後の結果を表示します。 実行する命令の文字列データの後ろにプログラムが続く形式の繰り返しです。多くの命令の実行結果を確認しているため長いですが、ほぼ同じこと繰り返しになっています。
//------------------------------------------------------------------------- // file : ldnstn.s // 2017/02/12 Jun Mizutani (https://www.mztn.org/) //------------------------------------------------------------------------- /* as -o ldnstn.o ldnstn.s ld -o ldnstn ldnstn.o ./ldnstn */ .global _start .include "float2string.s" .text _start: adr x1, S001 .data sld1_1: .asciz "ld1 { v1.s } [0], [x1] // LD1 single" .text adr x0, sld1_1 bl message bl clear_4v ld1 { v1.s }[0], [x1] bl print_1v bl NewLine .data sld1_1a: .asciz "ld1 { v1.s } [1], [x1] // LD1 single" .text adr x0, sld1_1a bl message bl clear_4v ld1 { v1.s }[1], [x1] bl print_1v bl NewLine .data sld1_1b: .asciz "ld1 { v1.s } [2], [x1] // LD1 single" .text adr x0, sld1_1b bl message bl clear_4v ld1 { v1.s }[2], [x1] bl print_1v bl NewLine .data sld1_1c: .asciz "ld1 { v1.s } [3], [x1] // LD1 single" .text adr x0, sld1_1c bl message bl clear_4v ld1 { v1.s }[3], [x1] bl print_1v bl NewLine .data sld1_2: .asciz "ld1 { v1.2s }, [x1] // LD1 multi 1reg" .text adr x0, sld1_2 bl message bl clear_4v ld1 { v1.2s }, [x1] bl print_1v bl NewLine .data sld1_3: .asciz "ld1 { v1.4s }, [x1] // LD1 multi 1reg" .text adr x0, sld1_3 bl message bl clear_4v ld1 { v1.4s }, [x1] bl print_1v bl NewLine .data sld1_4: .asciz "ld1r { v1.4s }, [x1] // LD1R" .text adr x0, sld1_4 bl message bl clear_4v ld1r { v1.4s }, [x1] bl print_1v bl NewLine .data sld1_5: .asciz "ld1 { v1.4s, v2.4s }, [x1] // LD1 multi 2reg" .text adr x0, sld1_5 bl message bl clear_4v ld1 { v1.4s, v2.4s }, [x1] bl print_2v bl NewLine .data sld1_6: .asciz "ld1 { v1.4s, v2.4s, v3.4s }, [x1] // LD1 multi 3reg" .text adr x0, sld1_6 bl message bl clear_4v ld1 { v1.4s, v2.4s, v3.4s }, [x1] bl print_3v bl NewLine .data sld1_0: .asciz "ld1 { v1.4s, v2.4s, v3.4s, v4.4s }, [x1] // LD1 multi 4reg" .text adr x0, sld1_0 bl message bl clear_4v ld1 { v1.4s, v2.4s, v3.4s, v4.4s }, [x1] bl print_4v bl NewLine .data sld2_1: .asciz "ld2 { v1.s, v2.s }[1], [x1] // LD2 single" .text adr x0, sld2_1 bl message bl clear_4v ld2 { v1.s, v2.s } [1], [x1] bl print_2v bl NewLine .data sld2_2: .asciz "ld2 { v1.2s, v2.2s }, [x1] // LD2 multi" .text adr x0, sld2_2 bl message bl clear_4v ld2 { v1.2s, v2.2s }, [x1] bl print_2v bl NewLine .data sld2_3: .asciz "ld2 { v1.4s, v2.4s }, [x1] // LD2 multi" .text adr x0, sld2_3 bl message bl clear_4v ld2 { v1.4s, v2.4s }, [x1] bl print_2v bl NewLine .data sld2_4: .asciz "ld2r { v1.4s, v2.4s }, [x1] // LD2 multi" .text adr x0, sld2_4 bl message bl clear_4v ld2r { v1.4s, v2.4s }, [x1] bl print_2v bl NewLine .data sld3_1: .asciz "ld3 { v1.s, v2.s, v3.s }[2], [x1] // LD3 single" .text adr x0, sld3_1 bl message bl clear_4v ld3 { v1.s, v2.s, v3.s }[2], [x1] bl print_3v bl NewLine .data sld3_2: .asciz "ld3 { v1.2s, v2.2s, v3.2s }, [x1] // LD3 multi" .text adr x0, sld3_2 bl message bl clear_4v ld3 { v1.2s, v2.2s, v3.2s }, [x1] bl print_3v bl NewLine .data sld3_3: .asciz "ld3 { v1.4s, v2.4s, v3.4s }, [x1] // LD3 multi" .text adr x0, sld3_3 bl message bl clear_4v ld3 { v1.4s, v2.4s, v3.4s }, [x1] bl print_3v bl NewLine .data sld3_4: .asciz "ld3r { v1.4s, v2.4s, v3.4s }, [x1] // LD3 multi" .text adr x0, sld3_4 bl message bl clear_4v ld3r { v1.4s, v2.4s, v3.4s }, [x1] bl print_3v bl NewLine .data sld4_1: .asciz "ld4 { v1.s, v2.s, v3.s, v4.s } [3], [x1] // LD4 single" .text adr x0, sld4_1 bl message adr x1, S001 bl clear_4v ld4 { v1.s, v2.s, v3.s, v4.s } [3], [x1] bl print_4v bl NewLine .data sld4_2: .asciz "ld4 { v1.4s, v2.4s, v3.4s, v4.4s }, [x1] // LD4 multi" .text adr x0, sld4_2 bl message adr x1, S001 bl clear_4v ld4 { v1.4s, v2.4s, v3.4s, v4.4s }, [x1] bl print_4v bl NewLine .data sld4_3: .asciz "ld4r { v1.4s, v2.4s, v3.4s, v4.4s }, [x1] // LD4 multi" .text adr x0, sld4_3 bl message adr x1, S001 bl clear_4v ld4r { v1.4s, v2.4s, v3.4s, v4.4s }, [x1] bl print_4v bl NewLine .data sld4_0: .asciz "ld4 { v1.s, v2.s, v3.s, v4.s }[1], [x1] // LD4 single (not cleared)" .text adr x0, sld4_0 bl message ld1 { v1.4s, v2.4s, v3.4s, v4.4s }, [x1] ld4 { v1.s, v2.s, v3.s, v4.s } [1], [x1] bl print_4v bl NewLine bl Exit //------------------------------------ clear_4v: movi v1.2D, #0 // clear v1 movi v2.2D, #0 // clear v2 movi v3.2D, #0 // clear v3 movi v4.2D, #0 // clear v4 ret print_1v: stp x0, x30, [sp, #-16]! adr x0, str_reg bl OutAsciiZ bl NewLine adr x0, str_v1 bl OutAsciiZ bl print_v1_4s ldp x0, x30, [sp], #16 ret print_2v: stp x0, x30, [sp, #-16]! str q1, [sp, #-16]! // save v1 bl print_1v adr x0, str_v2 bl OutAsciiZ mov v1.16b, v2.16b bl print_v1_4s ldr q1, [sp], #16 // restore v1 ldp x0, x30, [sp], #16 ret print_3v: stp x0, x30, [sp, #-16]! str q1, [sp, #-16]! bl print_2v adr x0, str_v3 bl OutAsciiZ mov v1.16b, v3.16b bl print_v1_4s ldr q1, [sp], #16 ldp x0, x30, [sp], #16 ret print_4v: stp x0, x30, [sp, #-16]! str q1, [sp, #-16]! bl print_3v adr x0, str_v4 bl OutAsciiZ mov v1.16b, v4.16b bl print_v1_4s ldr q1, [sp], #16 ldp x0, x30, [sp], #16 ret print_fixed15: stp x1, x30, [sp, #-16]! stp x2, x3, [sp, #-16]! bl Single2String mov x2, x0 mov x3, #15 bl StrLen sub x3, x3, x1 // x0 = 15 - StrLen(s0) mov x0, #0x20 1: bl OutChar sub x3, x3, #1 cbnz x3, 1b mov x0, x2 bl OutAsciiZ ldp x2, x3, [sp], #16 ldp x1, x30, [sp], #16 ret print_v1_4s: stp x0, x30, [sp, #-16]! mov s0, v1.s[3] bl print_fixed15 // print right s0, 15 mov s0, v1.s[2] bl print_fixed15 // print right s0, 15 mov s0, v1.s[1] bl print_fixed15 // print right s0, 15 mov s0, v1.s[0] bl print_fixed15 // print right s0, 15 bl NewLine ldp x0, x30, [sp], #16 ret message: stp x0, x30, [sp, #-16]! bl OutAsciiZ bl NewLine ldp x0, x30, [sp], #16 ret .data S001: .single 1.1345678E01 .single -2.2345678E02 .single 3.3345678E03 .single -4.4345678E04 .single 5.5345678E05 .single -6.6345678E06 .single 7.7345678E07 .single -8.8345678E08 .single 9.9345678E09 .single -1.0000111E10 .single 1.1000111E11 .single -1.2000111E12 .single 1.3000111E13 .single -1.4000111E14 .single 1.5000111E15 .single -1.6000111E16 .single 0 str_v1: .asciz " V1: " str_v2: .asciz " V2: " str_v3: .asciz " V3: " str_v4: .asciz " V4: " str_reg: .asciz " reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]" str_clear: .asciz "v1 - v4 cleared." str_loaded: .asciz "v1 - v4 value loaded."
float2string.s
今回の実行例では単精度浮動小数点を使っています。 前回の double2string.s では倍精度の表示だけでしたが、今回は単精度(8桁)、倍精度(16桁)両用の浮動小数点文字列変換として float2string.s を作成しました。double2string.s の上位互換です。
//------------------------------------------------------------------------- // file : float2string.s // 2017/01/31 Jun Mizutani (https://www.mztn.org/) //------------------------------------------------------------------------- .ifndef __STDIO .include "stdio.s" .endif .ifndef __D2STR __D2STR = 1 .text //------------------------------------------------------------------------- // single precision floating point number (s0) to asciiz string // x0 returns string address //------------------------------------------------------------------------- Single2String: stp x1, x30, [sp, #-16]! stp x2, x3, [sp, #-16]! stp x4, x5, [sp, #-16]! stp x6, x7, [sp, #-16]! stp q0, q1, [sp, #-32]! // save v0.2d, v1.2d stp q2, q3, [sp, #-32]! // save v2.2d, v3.2d stp q4, q5, [sp, #-32]! // save v4.2d, v5.2d mov x4, #0 // plus fcvt d0, s0 fcmp d0, #0.0 // check 0 b.eq _d2str_zero8 // d0 = 0.0 --> zero b.gt 1f fabs d0, d0 // if negative, d0 = abs(d0); x4=1 mov x4, #1 1: adr x7, num_buffer mov x0, #' ' cbz x4, 2f // if negative, print '-'s mov x0, #'-' 2: strb w0, [x7], #2 // additional space for decimal point bl _bin2decimal // mantissa should be 0.1 <= u < 1 ldr d2, Exp08 fmul d0, d0, d2 fcvtzu x4, d0 mov x0, x4 bl _put_uint8 // sub x0, x6, #1 // x0 = x6-1 cbz x0, _d2str_exit mov w1, #'E' strb w1, [x7], #1 bl _put_int // exponent b _d2str_exit _d2str_zero8: adr x7, num_buffer mov w0, #' ' strb w0, [x7], #2 // additional space for decimal point mov x0, xzr bl _put_uint8 b _d2str_exit //------------------------------------------------------------------------- // double precision floating point number (d0) to asciiz string // x0 returns string address //------------------------------------------------------------------------- Double2String: stp x1, x30, [sp, #-16]! stp x2, x3, [sp, #-16]! stp x4, x5, [sp, #-16]! stp x6, x7, [sp, #-16]! stp q0, q1, [sp, #-32]! // save v0.2d, v1.2d stp q2, q3, [sp, #-32]! // save v2.2d, v3.2d stp q4, q5, [sp, #-32]! // save v4.2d, v5.2d mov x4, #0 // plus fcmp d0, #0.0 // check 0 b.eq _d2str_zero16 // d0 = 0.0 --> zero b.gt 1f fabs d0, d0 // if negative, d0 = abs(d0); x4=1 mov x4, #1 1: adr x7, num_buffer mov x0, #' ' cbz x4, 2f // if negative, print '-'s mov x0, #'-' 2: strb w0, [x7], #2 // additional space for decimal point bl _bin2decimal // mantissa should be 0.1 <= u < 1 ldr d2, Exp16 fmul d0, d0, d2 fcvtzu x4, d0 mov x0, x4 bl _put_uint16 // sub x0, x6, #1 // x0 = x6-1 cbz x0, _d2str_exit mov w1, #'E' strb w1, [x7], #1 bl _put_int // exponent _d2str_exit: adr x0, num_buffer // shift left 1 digit for decimal point ldrb w1, [x0, #2] strb w1, [x0, #1] mov w1, #'.' strb w1, [x0, #2] ldp q4, q5, [sp], #32 // restore v4.2d, v5.2d ldp q2, q3, [sp], #32 // restore v2.2d, v3.2d ldp q0, q1, [sp], #32 // restore v0.2d, v1.2d ldp x6, x7, [sp], #16 ldp x4, x5, [sp], #16 ldp x2, x3, [sp], #16 ldp x1, x30, [sp], #16 ret _d2str_zero16: adr x7, num_buffer mov w0, #' ' strb w0, [x7], #2 // additional space for decimal point mov x0, xzr bl _put_uint16 b _d2str_exit //------------------------------------------------------------------------- // make mantissa (u:d0) between 0.1 and 1.0. (0.1 <= u < 1) // return exponent (v:x6) // f = n * 2 ^ m = u * 10 ^ v //------------------------------------------------------------------------- _bin2decimal: // n * 2^m = u * 10^v mov x6, #0 // exponent (v) mov x3, #TblSize mov x2, #512 // w = 512, v <= 1023 ldr d3, DOne // 1.00 --> d3 ldr d4, DTen // 10.0 --> d4 fcmp d0, d3 b.ge 4f // goto positive, if d0 >= 1.0 3: // negative exponent (f<1) sub x3, x3, #8 asr x2, x2, #1 // start from w=256 cbz x2, 6f // range01_1 adr x5, NegTable ldr d5, [x5, x3] fcmp d0, d5 // u > 10^-w b.ge 3b sub x6, x6, x2 // v = v - w fdiv d0, d0, d5 // u = u / 10^-w = u * 10^w b 3b 4: // positive exponent (f>=1) sub x3, x3, #8 asr x2, x2, #1 // w cbz x2, 5f // div 10 adr x5, PosTable ldr d5, [x5, x3] fcmp d0, d5 // u <= 10^n b.lt 4b add x6, x6, x2 // v = v + w fdiv d0, d0, d5 // u = u / 10^w b 4b 5: // div10 fdiv d0, d0, d4 // u = u / 10 add x6, x6, #1 // w = w + 1 6: ret //------------------------------------ // Output 16 digit unsigned number to buffer // x0 : number // x7 : buffer _put_uint16: stp x0, x30, [sp, #-16]! stp x1, x2, [sp, #-16]! stp x3, x4, [sp, #-16]! mov x2, xzr // counter 1: mov x1, #10 // x1 = 10 udiv x3, x0, x1 // division by 10 mul x4, x3, x1 sub x1, x0, x4 // x1 = x0 - x4*10 mov x0, x3 add x2, x2, #1 // counter++ str x1, [sp, #-16]! // least digit (reminder) cmp x2, #16 bne 1b // done ? b 2f //------------------------------------ // Output 8 digit unsigned number to buffer // x0 : number // x7 : buffer _put_uint8: stp x0, x30, [sp, #-16]! stp x1, x2, [sp, #-16]! stp x3, x4, [sp, #-16]! mov x2, xzr // counter 1: mov x1, #10 // x1 = 10 udiv x3, x0, x1 // division by 10 mul x4, x3, x1 sub x1, x0, x4 // x1 = x0 - x4*10 mov x0, x3 add x2, x2, #1 // counter++ str x1, [sp, #-16]! // least digit (reminder) cmp x2, #8 bne 1b // done ? b 2f //------------------------------------ // Output signed number to buffer // x0 : number // x7 : buffer _put_int: stp x0, x30, [sp, #-16]! stp x1, x2, [sp, #-16]! stp x3, x4, [sp, #-16]! mov x2, xzr // counter cmp x0, xzr b.ge 1f sub x0, x2, x0 // x0 = 0 - x0 mov w1, #'-' strb w1, [x7], #1 1: mov x1, #10 // x1 = 10 udiv x3, x0, x1 // division by 10 msub x1, x3, x1, x0 // x1 = x0 - x3*10 mov x0, x3 add x2, x2, #1 // counter++ str x1, [sp, #-16]! // least digit (reminder) cbnz x0, 1b // done ? 2: ldr x0, [sp], #16 // most digit add x0, x0, #'0' // ASCII strb w0, [x7], #1 // store a char into buffer subs x2, x2, #1 // counter-- bne 2b strb w2, [x7] // store 0 into buffer ldp x3, x4, [sp], #16 ldp x1, x2, [sp], #16 ldp x0, x30, [sp], #16 ret //============================================================== .data .align 3 DOne: .double 1.0 DTen: .double 10.000000000 NegTable: .double 1.0e-1 .double 1.0e-2 .double 1.0e-4 .double 1.0e-8 .double 1.0e-16 .double 1.0e-32 .double 1.0e-64 .double 1.0e-128 .double 1.0e-256 // 2^1023 < 10^308 PosTable: .double 1.0e+1 .double 1.0e+2 .double 1.0e+4 Exp08: .double 1.0e+8 Exp16: .double 1.0e+16 .double 1.0e+32 .double 1.0e+64 .double 1.0e+128 .double 1.0e+256 TblSize = . - PosTable .bss .align 2 num_buffer: .skip 32 .endif
実行結果
ldnstn.s、float2string.s、stdio.s を置いたディレクトリでアセンブル、リンク、実行します。
$ as -o ldnstn.o ldnstn.s
$ ld -o ldnstn ldnstn.o
$ ./ldnstn
ld1 { v1.s } [0], [x1] // LD1 single
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 0.0000000 0.0000000 0.0000000 1.1345678E1
ld1 { v1.s } [1], [x1] // LD1 single
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 0.0000000 0.0000000 1.1345678E1 0.0000000
ld1 { v1.s } [2], [x1] // LD1 single
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 0.0000000 1.1345678E1 0.0000000 0.0000000
ld1 { v1.s } [3], [x1] // LD1 single
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 1.1345678E1 0.0000000 0.0000000 0.0000000
ld1 { v1.2s }, [x1] // LD1 multi 1reg
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 0.0000000 0.0000000 -2.2345678E2 1.1345678E1
ld1 { v1.4s }, [x1] // LD1 multi 1reg
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: -4.4345679E4 3.3345678E3 -2.2345678E2 1.1345678E1
ld1r { v1.4s }, [x1] // LD1R
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 1.1345678E1 1.1345678E1 1.1345678E1 1.1345678E1
ld1 { v1.4s, v2.4s }, [x1] // LD1 multi 2reg
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: -4.4345679E4 3.3345678E3 -2.2345678E2 1.1345678E1
V2: -8.8345676E8 7.7345680E7 -6.6345680E6 5.5345674E5
ld1 { v1.4s, v2.4s, v3.4s }, [x1] // LD1 multi 3reg
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: -4.4345679E4 3.3345678E3 -2.2345678E2 1.1345678E1
V2: -8.8345676E8 7.7345680E7 -6.6345680E6 5.5345674E5
V3: -1.2000110E12 1.1000111E11 -1.0000110E10 9.9345674E9
ld1 { v1.4s, v2.4s, v3.4s, v4.4s }, [x1] // LD1 multi 4reg
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: -4.4345679E4 3.3345678E3 -2.2345678E2 1.1345678E1
V2: -8.8345676E8 7.7345680E7 -6.6345680E6 5.5345674E5
V3: -1.2000110E12 1.1000111E11 -1.0000110E10 9.9345674E9
V4: -1.6000111E16 1.5000111E15 -1.4000111E14 1.3000111E13
ld2 { v1.s, v2.s }[1], [x1] // LD2 single
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 0.0000000 0.0000000 1.1345678E1 0.0000000
V2: 0.0000000 0.0000000 -2.2345678E2 0.0000000
ld2 { v1.2s, v2.2s }, [x1] // LD2 multi
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 0.0000000 0.0000000 3.3345678E3 1.1345678E1
V2: 0.0000000 0.0000000 -4.4345679E4 -2.2345678E2
ld2 { v1.4s, v2.4s }, [x1] // LD2 multi
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 7.7345680E7 5.5345674E5 3.3345678E3 1.1345678E1
V2: -8.8345676E8 -6.6345680E6 -4.4345679E4 -2.2345678E2
ld2r { v1.4s, v2.4s }, [x1] // LD2 multi
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 1.1345678E1 1.1345678E1 1.1345678E1 1.1345678E1
V2: -2.2345678E2 -2.2345678E2 -2.2345678E2 -2.2345678E2
ld3 { v1.s, v2.s, v3.s }[2], [x1] // LD3 single
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 0.0000000 1.1345678E1 0.0000000 0.0000000
V2: 0.0000000 -2.2345678E2 0.0000000 0.0000000
V3: 0.0000000 3.3345678E3 0.0000000 0.0000000
ld3 { v1.2s, v2.2s, v3.2s }, [x1] // LD3 multi
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 0.0000000 0.0000000 -4.4345679E4 1.1345678E1
V2: 0.0000000 0.0000000 5.5345674E5 -2.2345678E2
V3: 0.0000000 0.0000000 -6.6345680E6 3.3345678E3
ld3 { v1.4s, v2.4s, v3.4s }, [x1] // LD3 multi
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: -1.0000110E10 7.7345680E7 -4.4345679E4 1.1345678E1
V2: 1.1000111E11 -8.8345676E8 5.5345674E5 -2.2345678E2
V3: -1.2000110E12 9.9345674E9 -6.6345680E6 3.3345678E3
ld3r { v1.4s, v2.4s, v3.4s }, [x1] // LD3 multi
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 1.1345678E1 1.1345678E1 1.1345678E1 1.1345678E1
V2: -2.2345678E2 -2.2345678E2 -2.2345678E2 -2.2345678E2
V3: 3.3345678E3 3.3345678E3 3.3345678E3 3.3345678E3
ld4 { v1.s, v2.s, v3.s, v4.s } [3], [x1] // LD4 single
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 1.1345678E1 0.0000000 0.0000000 0.0000000
V2: -2.2345678E2 0.0000000 0.0000000 0.0000000
V3: 3.3345678E3 0.0000000 0.0000000 0.0000000
V4: -4.4345679E4 0.0000000 0.0000000 0.0000000
ld4 { v1.4s, v2.4s, v3.4s, v4.4s }, [x1] // LD4 multi
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 1.3000111E13 9.9345674E9 5.5345674E5 1.1345678E1
V2: -1.4000111E14 -1.0000110E10 -6.6345680E6 -2.2345678E2
V3: 1.5000111E15 1.1000111E11 7.7345680E7 3.3345678E3
V4: -1.6000111E16 -1.2000110E12 -8.8345676E8 -4.4345679E4
ld4r { v1.4s, v2.4s, v3.4s, v4.4s }, [x1] // LD4 multi
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: 1.1345678E1 1.1345678E1 1.1345678E1 1.1345678E1
V2: -2.2345678E2 -2.2345678E2 -2.2345678E2 -2.2345678E2
V3: 3.3345678E3 3.3345678E3 3.3345678E3 3.3345678E3
V4: -4.4345679E4 -4.4345679E4 -4.4345679E4 -4.4345679E4
ld4 { v1.s, v2.s, v3.s, v4.s }[1], [x1] // LD4 single (not cleared)
reg Vn.S[3] Vn.S[2] Vn.S[1] Vn.S[0]
V1: -4.4345679E4 3.3345678E3 1.1345678E1 1.1345678E1
V2: -8.8345676E8 7.7345680E7 -2.2345678E2 5.5345674E5
V3: -1.2000110E12 1.1000111E11 3.3345678E3 9.9345674E9
V4: -1.6000111E16 1.5000111E15 -4.4345679E4 1.3000111E13
浮動小数点数の複数ロード/ストア命令は動きが複雑なため、 説明が非常に長くなってしまいました。 Arm64の浮動小数点演算の中で強力な機能であるベクトル演算(SIMD)において、 データの読み込みと結果の保存は避けては通れない機能なので、 時間をかけても理解する価値があると思います。